Bhavika Devnani
I’m a PhD student at Georgia Tech, advised by Judy Hoffman and James Hays. I’ve been lucky to explore different parts of machine learning through industry research roles at Apple AI/ML Research, Quora, and LinkedIn.
I’m interested in multimodal learning (vision, language, audio) and in making these models efficient, practical, and scalable.
Email | CV | Google Scholar | GitHub

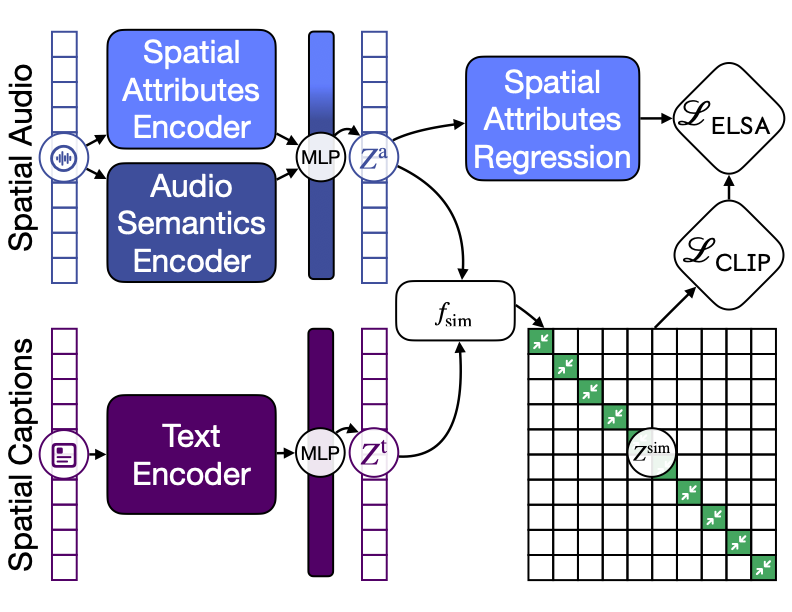
Bhavika Devnani, Skyler Seto, Zakaria Aldeneh, Alessandro Toso, Yelena Menyaylenko, Barry-John Theobald, Jonathan Sheaffer, Miguel Sarabia
Accepted at NeurIPS 2024
Generated dataset and trained a model to align 3D spatial audio with open vocabulary captions.
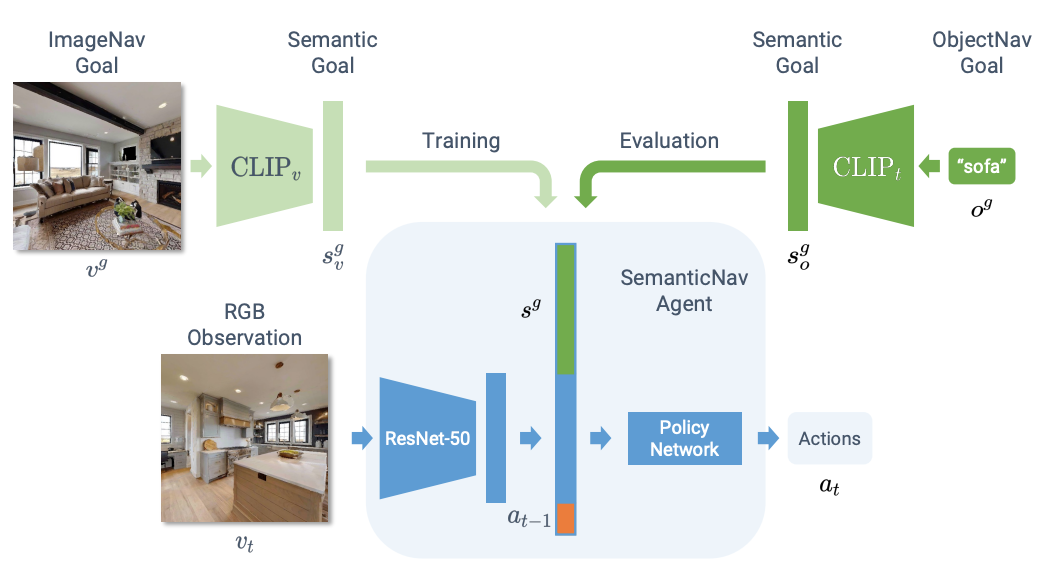
Arjun Majumdar*, Gunjan Aggarwal*, Bhavika Devnani, Judy Hoffman, Dhruv Batra
Accepted at NeurIPS 2022
CLIP enables Zero-Shot Object-Goal Navigation by learning multimodal goal embeddings.
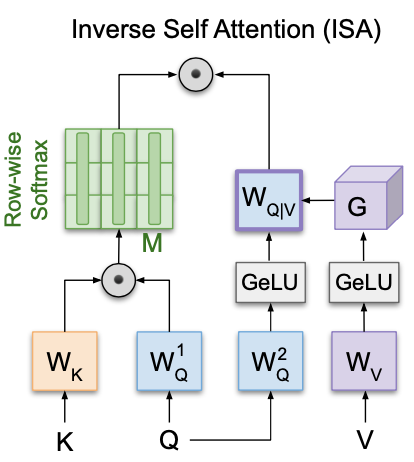
George Stoica, Taylor Hearn, Bhavika Devnani, Judy Hoffman
Accepted at NeurIPS 2022, Vision Transformers Workshop - Best Paper
Refined sources based on surrounding context by inverting self-attention.